
NDA: LLM
Автоматическое выявление и маркировка иноагентов/террористов в научных публикациях
Задача
Автоматизировать поиск упоминаний иноагентов/террористов и помечать их в любых текстовых источниках: веб-страницах, XML‑документах, PDF.
Что мы сделали
Мы разработали внутренний сервис, который на основе больших языковых моделей (LLM) автоматически:
– находит потенциальных иноагентов и террористов
– сверяет с базой данных сущностей
– помечает найденные совпадения специальными метками
– сохраняет результаты, индексирует и возвращает в удобной форме
– встраивает разметку прямо в текст статей, XML‑структуры и PDF-файлы
Сервис работает в реальном времени, интегрируется с существующими редакционными процессами и масштабируется под любой объём данных.
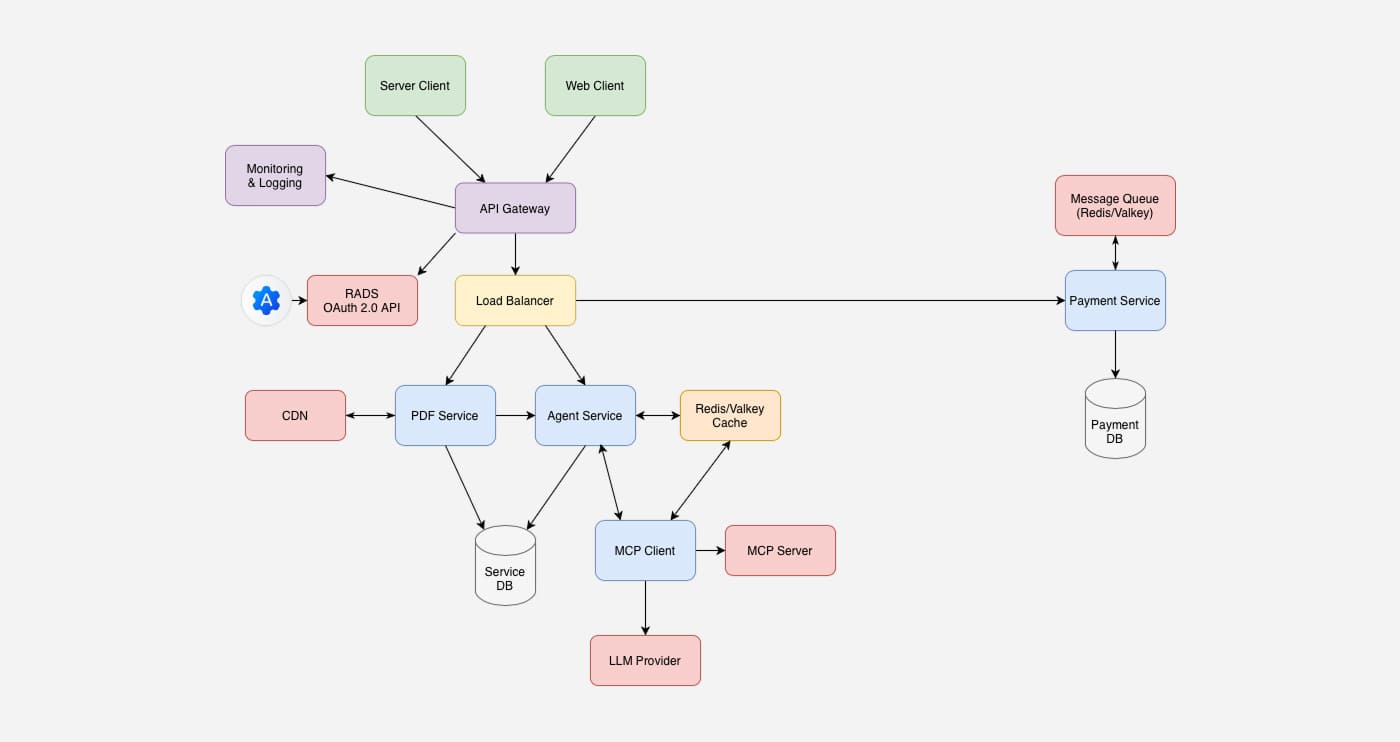
Как работает обработка веб‑страницы
1. Ищем текстовые теги, строим уникальные идентификаторы контента.
2. Отправляем фрагменты текста на сервер. Если ранее они уже обрабатывались — выдаём ответ из кэша и переходим к седьмому шагу.
3. Разбиваем контент на семантические куски.
4. Определяем сущности и их позиции с помощью Microsoft Presidio Analyzer (spaCy).
5. Проверяем результат в базе данных, исключая дубли и повторные вычисления.
6. Внедряем метки иноагентов: выделение, префиксы, знаки.
7. Отслеживаем прокрутку страницы и подгружаем новые фрагменты динамически.
Обработка XML
Логика идентична веб-версии, за исключением отсутствия шага с обновлением при прокрутке. Результат сразу возвращается как размеченный XML-файл.
Обработка PDF
OCR текста → распознаём содержимое PDF. Далее запускаем стандартный пайплайн как для веб-страниц.
В PDF добавляются аннотации с описанием найденных агентов — отображаются прямо в документе.

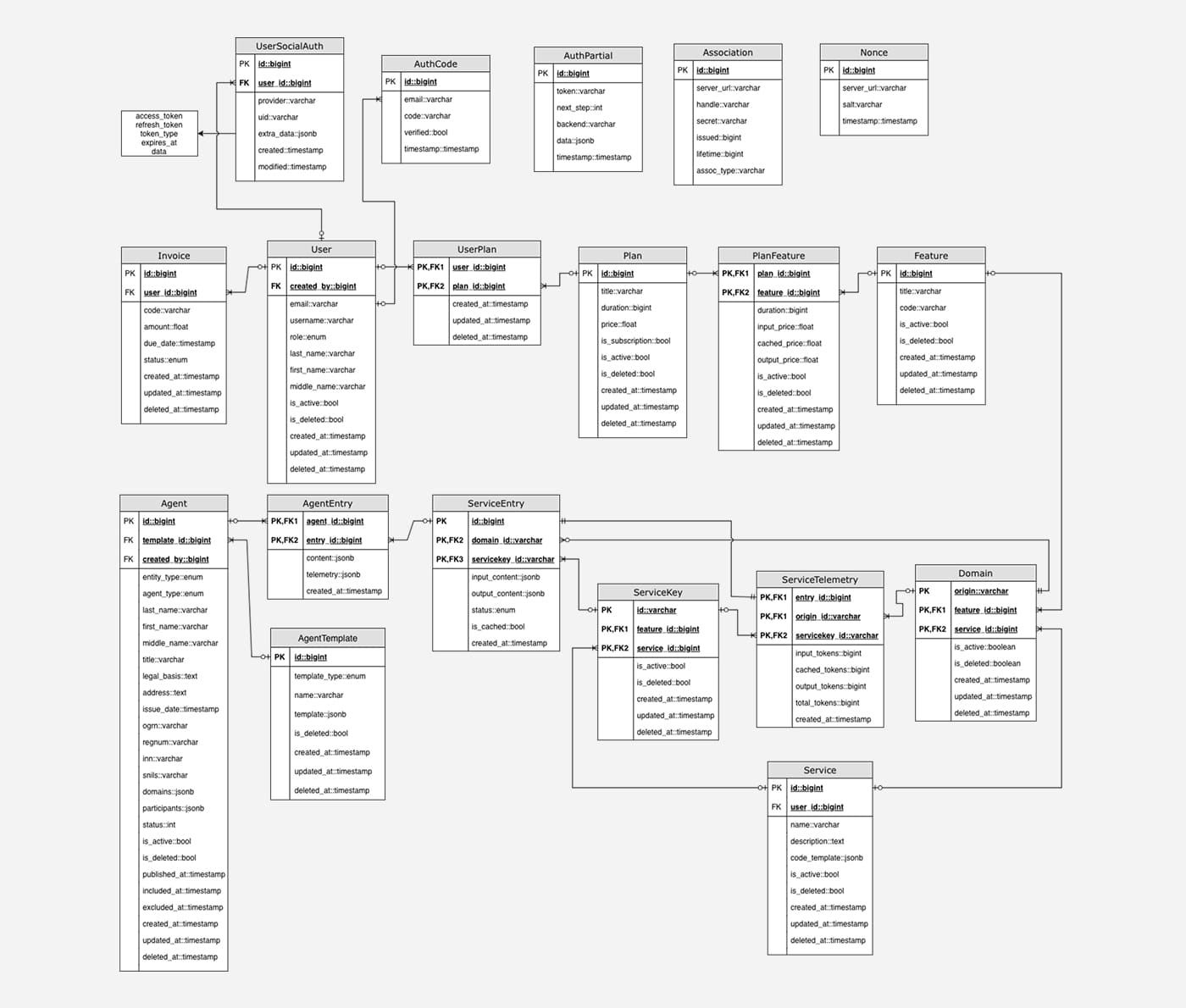
Результат
Автоматическая маркировка агентов в любых форматах текста.
Поддержка веб-страниц, XML, PDF с интерактивной разметкой.
Кеширование и быстрый повторный доступ
.
Масштабируемая архитектура с векторным поиском
.
Готовая интеграция с pipeline журнала и CMS.